
Künstliche Intelligenz im Kampf gegen Geldwäsche
Lukas Simon Gruber & Dr. Pooneh Pilvar & Lisa Glatzle
Abstract
Banken sind im Umfeld fortschreitender Digitalisierung mit einer steigenden Zahl an Finanztransaktionen konfrontiert und deshalb um eine effiziente Verarbeitung bemüht. Ein Bottleneck stellt die regulatorische Anforderung des Anti Money Launderings (AML) - Geldwäscheprävention - dar. Banken sind von Regulatoren dazu verpflichtet Finanztransaktionen auf deren Legitimität zu prüfen. Dazu muss ein großes Volumen an Transaktionsdaten analysiert werden, um Geldwäscheaktivitäten zu erkennen. Banken suchen nach Optimierungsmöglichkeiten unter Einsatz von technologischen und operativen Neuerungen. Eine dieser Neuerungen stellt die Künstliche Intelligenz (KI) dar. Durch die Kombination von steigender Rechenleistung und lernfähigen Algorithmen können große Datenmengen effizient verarbeitet werden. So werden Kosten sowie manueller Aufwand eingespart und die Prüfung von Transaktionen dynamischer und schneller abgeschlossen.
Voraussetzungen für den Einsatz Künstlicher Intelligenz
Die Künstliche Intelligenz (KI) ist eine aktuelle Thematik mit stetig wachsender Aufmerksamkeit, die weltweit über viele Branchen hinweg an Bedeutung gewinnt. Die Europäische Kommission bezeichnet KI als Schlüsseltechnologie für wirtschaftliches Wachstum und strebt eine weltweite Führungsrolle an, um Vorteile für Menschen, Unternehmen und Regierungen zu realisieren. Mit den Innovationsprogrammen „Digitales Europa“ und „Horizont Europa“ will die Kommission pro Jahr 1 Milliarde Euro investieren und zeitgleich mehr als 20 Milliarden Euro jährlich an Investitionen in KI aus Mitgliedsstaaten und dem privaten Sektor mobilisieren [Europäische Kommission, 2021]. Ein Themengebiet, das mit der KI Hand in Hand geht, ist Big Data. Big Data umfasst nach dem 3V-Modell (engl. Volume, Velocity und Variety) Daten, die hohes Volumen aufweisen, schnell produziert werden und eine große Informationsvielfalt umfassen. Genau in diesem datengetriebenen Umfeld kommen die Vorteile von KI Modellen zum Tragen. Je höher die Quantität und Qualität der zugrundeliegenden Daten ist, umso besser können die Modelle trainiert werden. Auf diese Weise bedingen sich die beiden Disziplinen gegenseitig und machen es möglich Prozesse zu automatisieren [BaFin, 2018]. In der Bankenbranche werden besonders im Zahlungsverkehr große Mengen an Transaktionsdaten verarbeitet. Die 3Vs treffen auf diese Daten zu. Allein über das SWIFT Netzwerk werden durchschnittlich 37,9 Millionen Transaktionsnachrichten täglich zwischen weltweit mehr als 11.000 teilnehmenden Banken versendet. Die Geschwindigkeit der Transaktionsverarbeitung wird maßgeblich beeinflusst durch die Überprüfung jeder Zahlung auf Legalität und Compliance. Ein Teil dieser Prüfung stellt das Anti Money Laundering (AML) dar. In den AML Prozessen wird eine Vielzahl an Transaktionen analysiert und ein hoher Anteil dieser Prüfungen wird händisch durchgeführt. Eine Automatisierung des Prozesses geht einher mit relevanten Kosteneinsparungen und Effizienzgewinnen [BaFin, 2018].
Geldwäsche und Anti-Money Laundering
Durch Geldwäsche wird die Herkunft von illegal erwirtschaftetem Geld verschleiert. So kann es im legalen Wirtschaftskreislauf genutzt werden, ohne dass Behörden darauf aufmerksam werden. Das 3 Phasen-Modell in Abbildung 1 zeigt das allgemein zugrundeliegende Schema der Geldwäsche.
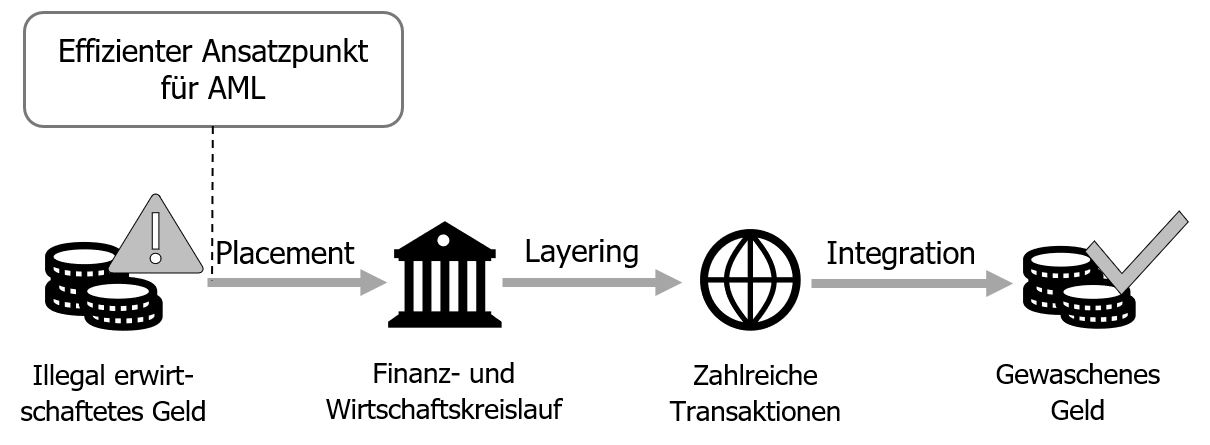 Abbildung 1: Die drei Phasen der Geldwäsche (eigene Darstellung)
Abbildung 1: Die drei Phasen der Geldwäsche (eigene Darstellung)
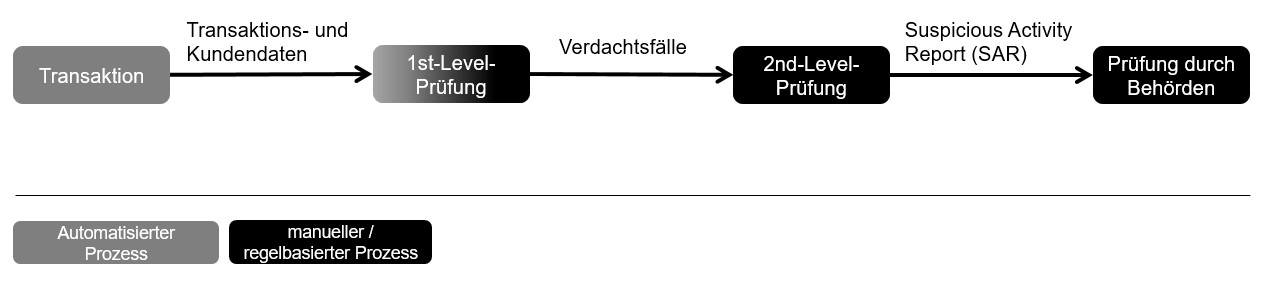 Abbildung 2: Meldung von verdächtigen Transaktionen [BaFin, 2018]
Abbildung 2: Meldung von verdächtigen Transaktionen [BaFin, 2018]
In Deutschland wurden im Jahr 2018 über 77.000 Verdachtsmeldungen an die FIU weitergegeben. Dieser Wert hat sich im Vergleich zum Jahr 2008 fast verzehnfacht. Bei 42% der Meldungen lagen nicht die Voraussetzungen für einen Verdachtsfall vor, was auf Verbesserungsspielräume bei Banken und Finanzdienstleistungsinstituten hindeutet, welche für über 99% der Meldungen verantwortlich sind. 2% dieser über 77.000 Meldungen endeten in Urteilen, Strafbefehlen oder Anklageschriften zum Tatbestand der Geldwäsche. Allerdings werden bei dieser Statistik Fälle nicht erfasst, bei denen zwar der Tatbestand der Geldwäsche nicht weiterverfolgt wurde, jedoch durch die Meldung die Vortat aufgedeckt werden konnte [Generalzolldirektion Financial Intelligence Unit, 2019]. Die im 1st-Level angewendeten regelbasierten Systeme haben Schwächen: Durch die Regeln werden neben den kriminellen Transaktionen auch eine Vielzahl an legitimen Transaktionen herausgefiltert. Bei den fälschlich als verdächtig gemeldeten Transaktionen wird von falsch positiv Meldungen gesprochen. Der Anteil dieser liegt bei über 90% [Ketenci, et al., 2021]. Der Begriff falsch positiv entspringt der Confusion Matrix (siehe Abbildung 3). Sie dient dazu, Entscheidungen eines Modells zu gruppieren. Es wird überprüft, ob die Vorhersage des Modells mit der Wirklichkeit übereinstimmt. Korrekte Ergebnisse sind richtig positive und richtig negative. Im Kontext der Geldwäscheerkennung entspricht das einer korrekt identifizierten Geldwäschetransaktion oder einer korrekt identifizierten legitimen Transaktion.
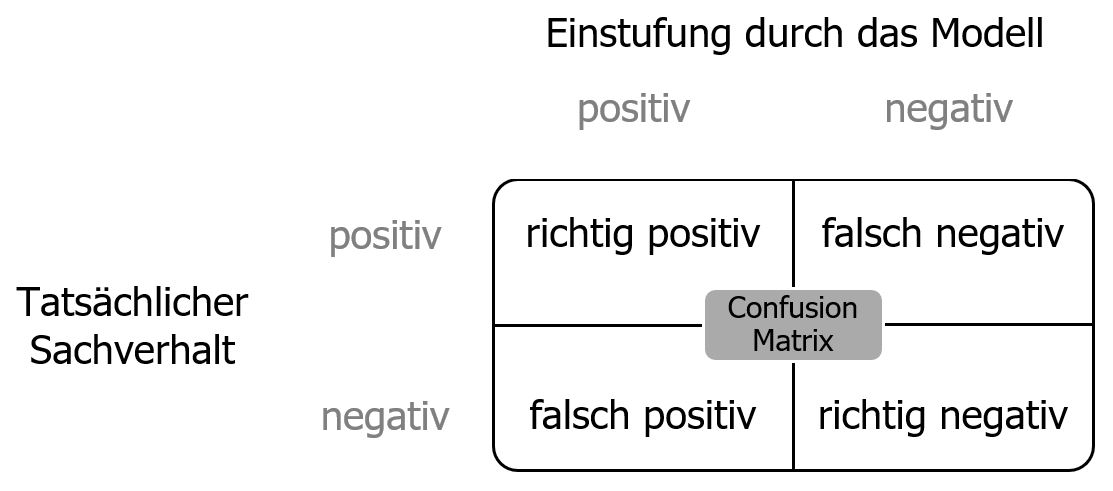 Abbildung 3: Confusion Matrix (eigene Darstellung)
Abbildung 3: Confusion Matrix (eigene Darstellung)
Als kritisch anzusehen sind falsch negative Entscheidungen von Modellen. Das entspricht bei AML einer verdächtigen Transaktion, die nicht erkannt wird. Die falsch negativen zu eliminieren ist schwierig, falls Kriminelle, möglicherweise durch Insider, Kenntnisse über die eingesetzten Regeln haben [Ketenci, et al., 2021]. Die Anzahl an nicht aufgedeckten Geldwäschetransaktionen wird sehr hoch eingeschätzt: Weniger als 1% der über das Finanzsystem gewaschenen Gelder sollen in der Vergangenheit beschlagnahmt oder eingefroren worden sein [UNODC, 2011]. Probleme entstehen auch durch eine hohe Anzahl an falsch positiven Fällen. Viele falsch positive Bewertungen führen zu einem hohen manuellen Zusatzaufwand, da diese im 2nd-Level als legitime Transaktionen herausgefiltert werden müssen. Verbesserungen können aus einer optimierten Erkennung der Geldwäschetransaktionen resultieren. Damit steigt die Quote der richtig positiven Fälle. Ebenfalls ergeben sich Verbesserungen durch die Minimierung von falsch positiven Fällen.
Künstliche Intelligenz im Anti-Money Laundering
Getrieben durch den stetigen technologischen Fortschritt geht der Trend hin zu einer immer höheren Anzahl an Finanztransaktionen mit steigenden Transaktionsvolumina. Zusätzlich wird eine zunehmend schnellere Verarbeitung erwartet. Damit bei der steigenden Geschwindigkeit ein Monitoring bezüglich krimineller Transaktionen stattfinden kann, ist es notwendig den Monitoringprozess zu beschleunigen und zu automatisieren. Eine Möglichkeit das zu gewährleisten, stellt der Einsatz von KI dar. Der umfassende Begriff KI kann untergliedert werden in starke und schwache KI. Eine starke KI imitiert uns Menschen und erreicht unsere Fähigkeiten, unser Wissen und unsere Kreativität in jeder Hinsicht oder übersteigt diese. Die Entwicklung einer echten starken KI ist noch nicht absehbar. Im Gegensatz dazu handelt es sich bei einer schwachen KI anwendbare Methoden und Algorithmen, die in spezialisierten Fällen eingesetzt werden, beispielsweise zur Mustererkennung oder Datenanalyse. Folglich ist die schwache KI als technisches Hilfsmittel zu betrachten, welches nur unter den benötigten Grundvoraussetzungen und angepasst an den gewählten Anwendungsfall effizient funktioniert. Der Begriff Machine Learning (ML) beschreibt eine Untergruppe von KI. Charakterisierend ist die Fähigkeit mit Hilfe von bereitgestellten Daten ein Modell zu erstellen, mit dessen Hilfe Aufgaben automatisiert bearbeitet werden. Ein Vorteil von ML Modellen ist die Fähigkeit sich dynamisch an neue Daten anzupassen. Bekannte Daten werden im Lernprozess genutzt um auf neue Daten zu reagieren und die gewünschten Ergebnisse und Entscheidungen zu liefern. Unterstützt von zunehmender Rechenleistung ist es mit ML Algorithmen möglich große Datenmengen zu verarbeiten. Spezialisiert auf komplexe Mustererkennung, die Erkennung von Anomalien oder Clusterung der Daten sind ML Algorithmen geeignet um Geldwäscheaktivitäten zu erkennen [Yan Zhang, 2018]. Unterschiedliche Arten des Lernens kommen bei ML zum Einsatz. Bei supervised learning wird das Modell anhand eines Datensatzes trainiert, der alle nötigen Inputparameter sowie den korrekten Output liefert. Bei unsupervised learning hingegen werden nur Inputparameter zur Verfügung gestellt. Vorgaben zum erwarteten Output werden nicht übergeben. Stattdessen sollen vorliegende Muster im Datensatz erkannt werden [BaFin, 2018]. Um ML erfolgreich einzusetzen bedarf es gewisser Vorbereitungen. Die BaFin hat diese für den Anwendungsfall AML dargestellt. Zuerst werden die zu erfüllenden Ziele festgelegt. Bei AML ist zum Beispiel eine Zielvorgabe die Kosten zu minimieren. Ein alternatives Ziel ist es, die Anzahl der falsch positiven Meldungen zu minimieren oder mehr kriminelle Transaktionen herauszufiltern, ergo die Quote der richtig positiven Meldungen zu erhöhen [BaFin, 2018]. Eine weitere Vorbereitungsmaßnahme ist die Aufbereitung erforderlicher Daten. Die KI ist auf diese Daten angewiesen – es ist also entscheidend, dass an dieser Stelle das vorhandene Fachwissen genutzt wird, um alle relevanten Transaktionsdaten zu identifizieren und mögliche Zusatzinformationen einzubinden. Sind alle notwendigen Voraussetzungen erfüllt und die KI trainiert, gilt es anschließend das Modell mit einem neuen Datensatz zu testen [BaFin, 2018]. In einer empirischen Studie von Zhang und Trubey wurden mehrere supervised ML Algorithmen anhand von Transaktionsdaten eines amerikanischen Finanzinstituts analysiert und bezüglich deren Effizienz für AML miteinander verglichen. Klassische Methoden wurden als Benchmark genutzt. Die Daten umfassten einen Zeitraum von 13 Monaten und beinhalteten fast 100 verschiedene Parameter. Die ersten acht Monate wurden dabei für die Lernphase der supervised ML Modelle genutzt. Weil es sich um supervised Learning handelt, wurden die Transaktionsdaten sowie das Ergebnis, ob es sich tatsächlich um Geldwäsche handelt, als Input eingespeist. Die folgenden KI Methoden wurden für die Studie genutzt:
- Bayes Logistic Regression: Das Ziel von statistischer Regression ist es einen Zusammenhang zwischen den gegebenen Variablen festzustellen und für das Regressionsmodell zu gewichten. Bayes Logistic Regression Modelle sind besonders geeignet um Entscheidungen anhand binärer Klassifizierungen zu treffen. Bei der Bayes Logistic Regression werden dafür sowohl Informationen genutzt, die vorab bekannt sind, als auch die Informationen aus den Inputdaten.
- Decision Tree: Das Decision Tree Modell besteht aus hierarchisch aufgebauten Entscheidungen anhand von Attributen, die zu einer schrittweisen Klassifizierung der Inputdaten führt. Anhand der Klassifizierung wird eine Entscheidung getroffen. Der Inhalt sowie die Anzahl der Entscheidungsregeln vor einer Klassifizierung können variieren. Ein Vorteil dieser Methode ist die Interpretierbarkeit einer Lösung. Jede Klassifizierung kann anhand der einzelnen Entscheidungen jederzeit nachvollzogen werden. Jedoch können kleine Änderungen in den Inputdaten zu große Änderungen im Modell nach sich ziehen. Dadurch sind Decision Tree Modelle oftmals unpräzise.
- Random Forest: Die Entscheidung aus mehreren unterschiedlich aufgebauten Decision Trees wird zu einer gemeinsamen Entscheidung zusammengeführt. Es wird als esemble Modell bezeichnet. Durch die Berücksichtigung mehrerer Decision Trees wird die Präzision erhöht. Die Interpretierbarkeit nimmt dadurch ab und die Trainingsphase des Modells wird mit steigender Anzahl an berücksichtigten Decision Trees länger.
- Support Vector Machine: Eine Klassifizierung findet statt, indem der Raum der Inputdaten mit Hyperebenen und zugehörigen Support Vektoren aufgeteilt wird. Es wird darauf geachtet eine möglichst deutliche Zuordnung jedes Datenpunktes zu einer Klasse zu erreichen. Bei Support Vector Machine Modellen besteht eine große Abhängigkeit zu den Inputdaten. Je deutlicher sich einzelne Klassifizierungen in den Inputdaten voneinander abgrenzen umso effizienter ist diese Methode.
- Artificial Neural Network: Als biologisches Vorbild für dieses Modell dient das menschliche Gehirn. Um eine Entscheidung zu treffen durchlaufen die Inputdaten ein Netzwerk aus künstlichen Synapsen deren Verbindungen verschiedene Gewichtungen erhalten. Die Modelle bestehen aus einem Input Layer am Anfang und am Ende aus einem Output Layer. Dazwischen befinden sich die verbundenen Synapsen, welche als Hidden Layer bezeichnet werden. Im Trainingsstadion werden die Verbindungen und deren Gewichtungen stetig angepasst. Aufgrund des spezifischen Aufbaus des Modells ist es schwerer die Ergebnisse zu interpretieren. Zum Vergleich der Methoden wurden diverse Simulationen durchgeführt und der Parameter Area under the ROC Curve (AUC) für verschiedene Datensätze ermittelt. Weil der AUC Wert je nach Beschaffenheit des Datensatzes variiert, spannen sich mehrere Dimensionen auf. Besonders ausschlaggebend ist hier die Ereignisrate. Als Ereignisrate wird der relative Anteil statistischer Treffer bezeichnet. In diesem Fall wie hoch der relative Anteil an tatsächlichen Geldwäschefällen innerhalb des Datensatzes ist. Verglichen wird relativ zur Benchmark. Gesamtheitlich betrachtet liefern Artificial Neural Network sowie Bayes Logistic Regression eine bessere Performance ab als der Benchmark. Random Forest und Support Vector Machine Modelle sind erst bei Ereignisraten über 10% besser als der Benchmark. Decision Tree Modelle performen in den meisten Fällen schlechter als der Benchmark [Yan Zhang, 2018]. Dieser Vergleich zeigt, dass KI nicht grundsätzlich überlegen ist, sondern gezielt und unter den richtigen Voraussetzungen eingesetzt werden muss. Modelle, welche erst bei höheren Ereignisraten performen, sollten erst bei der 2nd-Level Prüfung eingesetzt werden (siehe Abbildung 4). Eine erfolgreiche 1st-Level Prüfung ist dann notwendig. Sind die richtigen Bedingungen erfüllt, steigt die gesamtheitliche Performance des Prüfprozesses.
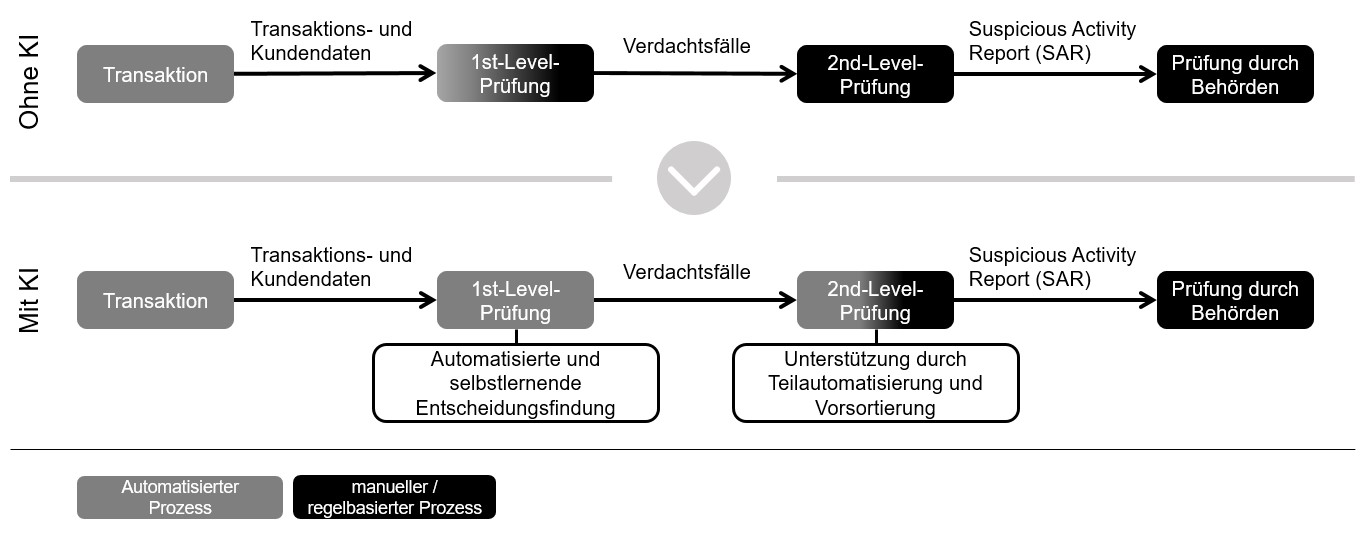 Abbildung 4: Optimierungsmöglichkeiten im AML Prüfprozess durch KI [BaFin, 2018]
Abbildung 4: Optimierungsmöglichkeiten im AML Prüfprozess durch KI [BaFin, 2018]
KI Methoden in AML hat das SAS Institute mehrfach realisiert. Die falsch positiv Fälle konnten bei einer asiatischen Bank auf 1st-Level Ebene um 33% gesenkt werden. Bei einer amerikanischen Bank realisierte SAS mit einem Artificial Neural Network Modell einen Rückgang der falsch positiv Fälle von 50% bei einer gleichzeitigen Steigerung der SAR Rate von 5% auf 15%. Mit Hilfe von KI Anwendungen identifizierte eine globale Bank 89 bisher unbekannte kriminelle Kunden, somit wurden die falsch negativen Fälle reduziert [SAS, 2019]. Ein weiteres erfolgreiches KI System wurde von teradata bei der dänischen Danske Bank implementiert. Mit Hilfe von KI Systemen werden Anomalien und potentiell betrügerische Aktivitäten erkannt. In Einzelfällen ist weiterhin eine menschliche Beurteilung notwendig. Dieses System senkte die falsch positiv Fälle um 60% und erkannte 50% mehr tatsächliche Betrugsfälle [teradata, 2020].
Hürden beim Einsatz von Künstlicher Intelligenz
Der Weg zu einem breiten und effizienten Einsatz von KI birgt auch einige Hürden, die es zu überwinden gilt.
- Nachvollziehbarkeit: Bezogen auf Compliance soll die KI nicht als Black Box agieren. Black Box bezeichnet eine Eigenschaft von Algorithmen, bei denen der Lösungsweg oder die Entscheidungsfindung auf Grund von hoher Komplexität und Dynamik unbekannt ist. Die Ergebnisse und Entscheidungen, die in den Systemen der Bank getroffen werden und einer umfassenden Regulatorik unterliegen, müssen erklärbar sein. Speziell Regulierungsbehörden müssen die Abläufe nachvollziehen können, damit sie das System als compliant bewerten können. KI Algorithmen, die kein Black Box Verhalten aufweisen, fallen in den Sektor Explainable Artificial Intelligence (XAI). Die Erklärbarkeit stellt dabei nicht nur eine regulatorische Pflicht dar, sondern bietet auch die Chance den Prozess durch Analysen zu verbessern.
- Qualität des Modells: Over- oder Underfitting tritt ein, wenn ein Modell mit den Testdaten zu sehr spezialisiert oder zu allgemein trainiert wurde. Das wirkt sich negativ auf die Performance des KI Modells aus. Ein Bias tritt auf, wenn die Testdaten einen systematischen Fehler aufweisen und folglich von der KI übernommen werden [BaFin, 2018]. Probleme von KI Modellen wie Over-/Underfitting oder Biases können schneller erkannt und behoben werden, wenn sie nicht als Black Box agieren.
- Datenschutz: In der DSGVO wird speziell nach Datenminimierung und Zweckbindung von Daten verlangt. Produkte und Dienstleistungen, die auf KI basieren, sind jedoch neben der Qualität auch von der Quantität der Daten abhängig. Hier muss die richtige Balance gefunden werden, um den Datenschutz einzuhalten und gleichzeitig Vorteile von KI Methoden nutzen zu können. Anonymisierung bzw. Pseudonymisierung der Daten kann eine mögliche Lösung für das Problem darstellen.
Ausblick
Es wurden bereits Best Practices entwickelt, um eine größere Bandbreite an Daten und Informationen zu nutzen, ohne mit der DSGVO in Konflikt zu geraten: Diese basieren zumeist auf einer engen Zusammenarbeit zwischen öffentlichem und privatem Sektor. Im Rahmen von public private financial information-sharing partnerships (FISP) werden komplexe Fälle behandelt und aufgedeckt. Die erste FISP wurde bereits 2015 in Großbritannien umgesetzt. Seitdem folgen weltweit ähnliche Initiativen. Deutschland ist dabei mit einem 2019 in die Pilotphase gestarteten FISP ein Nachzügler und beschränkt sich zudem auf „Strategic Intelligence Co-development“. Damit ist die Wirksamkeit der Initiative beschränkt im Vergleich zu sowohl strategisch, als auch taktisch ausgelegten FISPs, welche international weiter verbreitet sind [RUSI, 2020]. Die Tendenz des steigenden Einsatzes von KI Systemen im Zahlungsverkehr und allgemeiner der Bankenbranche wird durch die beschriebenen Hürden nicht gebremst. Die Organisation for Economic Co-operation and Development (OECD) stellt fest, dass der Finanzsektor bei den Investitionsvolumen in KI unter den Top 10 aller Industriezweige rangiert. Gleichzeitig ruft die OECD dazu auf mit noch größerem Aufwand Vertrauen zu schaffen, um einen breiteren und effizienteren Einsatz von KI zu realisieren [OECD, 2021]. Effizienzgewinne sind durch KI Methoden realisierbar, welche auf eine zügigere Verarbeitung der Finanztransaktionen einzahlen und manuelle Aufwände minimieren können. Dabei sollte nicht die Erwartungshaltung bestehen mit einer beliebigen KI Methode alle Ineffizienzen beheben zu können. Eine realistische Einschätzung der Gegebenheiten wie regulatorische Anforderungen oder Qualität, Quantität und Beschaffenheit der Daten ist notwendig, um die richtige Methodik zu wählen. Sind die Voraussetzungen erfüllt, stellt die KI einen modernen Lösungsweg zu einer effizienteren AML dar.



References
BaFin. (2018). Big Data trifft auf künstliche Intelligenz - Herausforderungen und Implikationen für Aufsicht und Regulierung von Finanzdienstleistungen. https://www.bafin.de/SharedDocs/Downloads/DE/dl_bdai_studie.html: BaFin.
Bolton, R., & Hand, D. (2002). Statistical Fraud Detection: A Review. Statistical Science, S. 235-255.
Europäische Kommission. (29. 11 2021). ec.europa.eu. Von https://ec.europa.eu/info/strategy/priorities-2019-2024/europe-fit-digital-age/excellence-trust-artificial-intelligence_de abgerufen Generalzolldirektion Financial Intelligence Unit. (2019). Jahresbericht 2018. Köln.
Ketenci, U. G., Kurt, T., Önal, S., Erbíl, C., Aktürkoğlu, S., & Ílhan, H. Ş. (26. April 2021). A Time-Frequency Based Suspicious Activity Detection for Anti-Money Laundering. IEEE Access, S. 59957-59967.
LexisNexis Risk Solutions. (2017). The True Cost Of Anti-Money Laundering Compliance.
OECD. (2021). OECD Business and Finance Outlook 2021: AI in Business and Finance. Paris: OECD Publishing.
RUSI. (2020). Five years of growth in public-private financial information-sharing partnerships to tackle crime.
SAS. (2019). How AI and Machine Learning Are Redefining Anti-Money Laundering. SAS.
Statista. (2022). Von https://de.statista.com/statistik/daten/studie/159798/umfrage/entwicklung-des-bip-bruttoinlandsprodukt-weltweit/#professional abgerufen
teradata. (23. Juni 2020). Danske Bank Fights Fraud with Deep Learning and AI. Von https://assets.teradata.com/resourceCenter/downloads/CaseStudies/CaseStudy_EB9821_Danske_Bank_Fights_Fraud.pdf abgerufen
UNODC. (2011). Estimating illicit financial flows resulting from drug trafficking and other transnational organized crimes. Wien.
Yan Zhang, P. T. (2018). Machine Learning and Sampling Scheme: An Empirical. Computational Economics.